We introduce the task of weakly supervised learning for detecting human and object interactions in videos. Our task poses unique challenges as a system does not know what types of human-object interactions are present in a video or the actual spatiotemporal location of the human and object. To address these challenges, we introduce a contrastive weakly supervised training loss that aims to jointly associate spatiotemporal regions in a video with an action and object vocabulary and encourage temporal continuity of the visual appearance of moving objects as a form of self-supervision. To train our model, we introduce a dataset comprising over 6.5k videos with human-object interaction annotations that have been semi-automatically curated from sentence captions associated with the videos. We demonstrate improved performance over weakly supervised baselines adapted to our task on our video dataset.

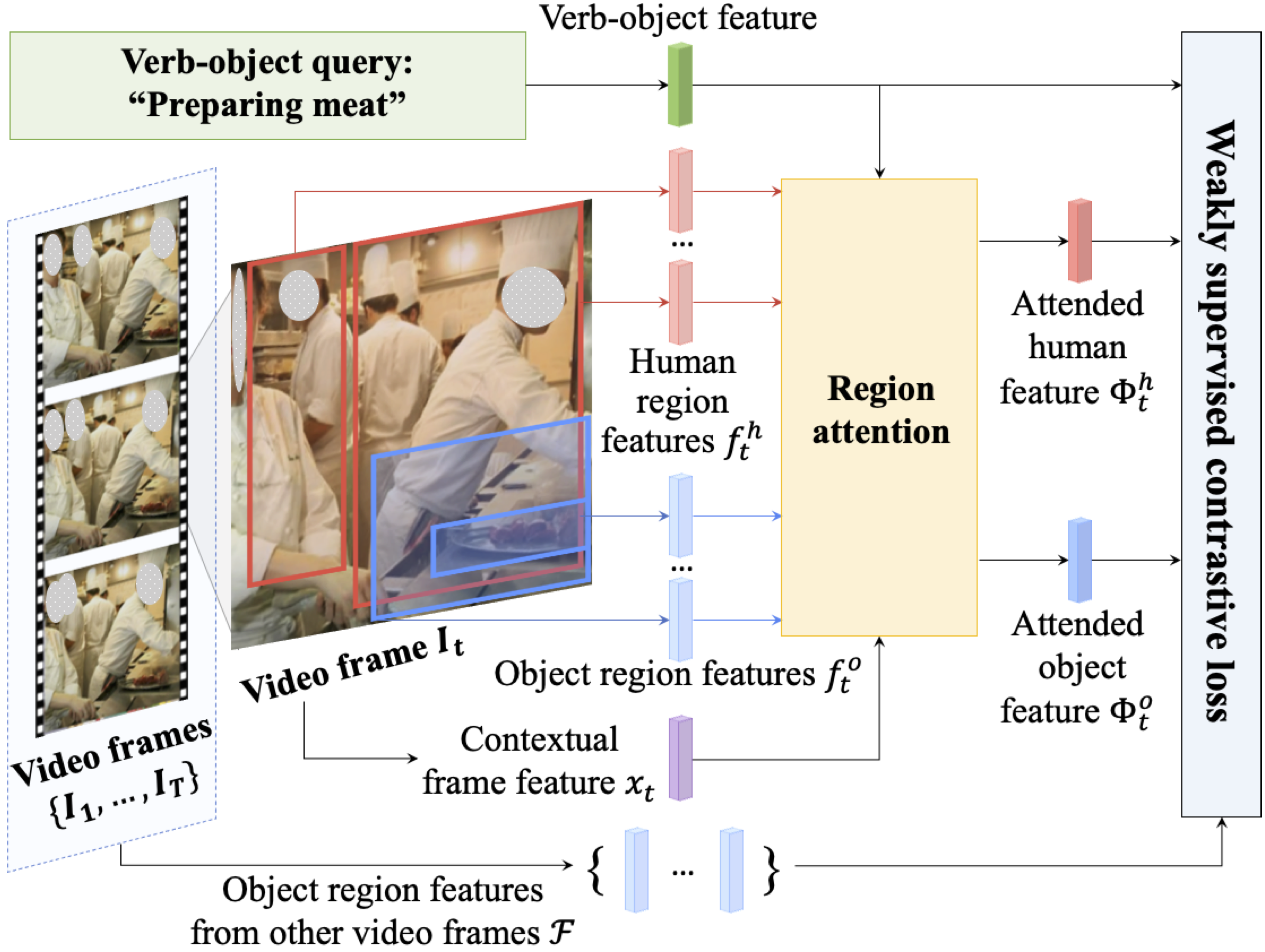
Training Overview
Given a video clip and a verb-object query, for each frame, we first extract its human and object region features. The human/object features are aggregated after a region attention module. The attended human feature, attended object feature, the feature of verb-object query, and object region features from other frames are used to compute our weakly supervised contrastive loss.
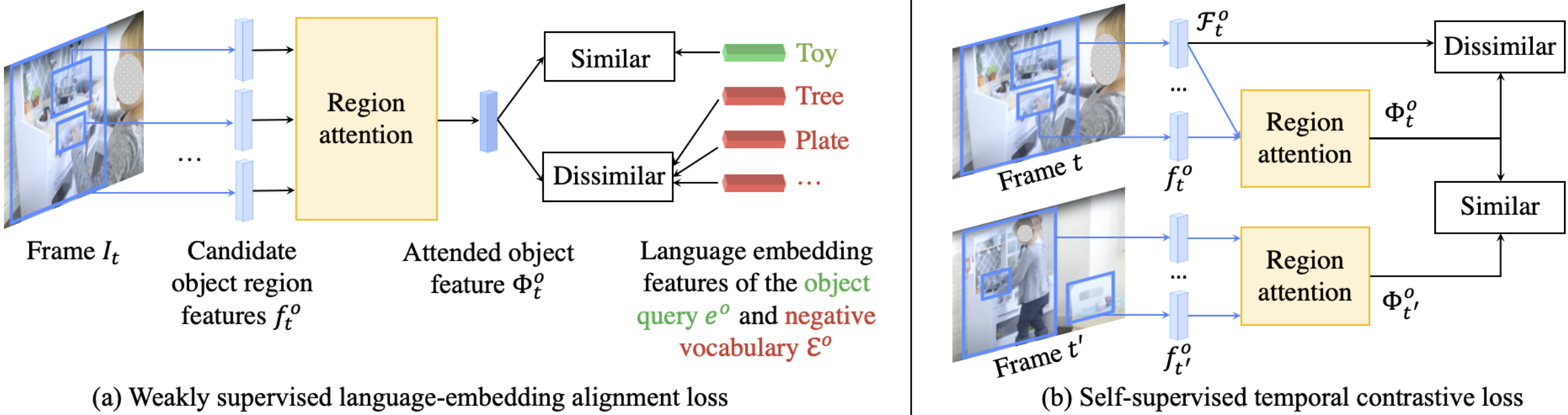
Weakly supervised contrastive loss
Our loss jointly aligns features for spatiotemporal regions in a video to (a) a language-embedding feature for an input verb-object query and (b) other spatiotemporal regions likely to contain the target object. This figure only shows object regions. The same thing is applied to human regions.
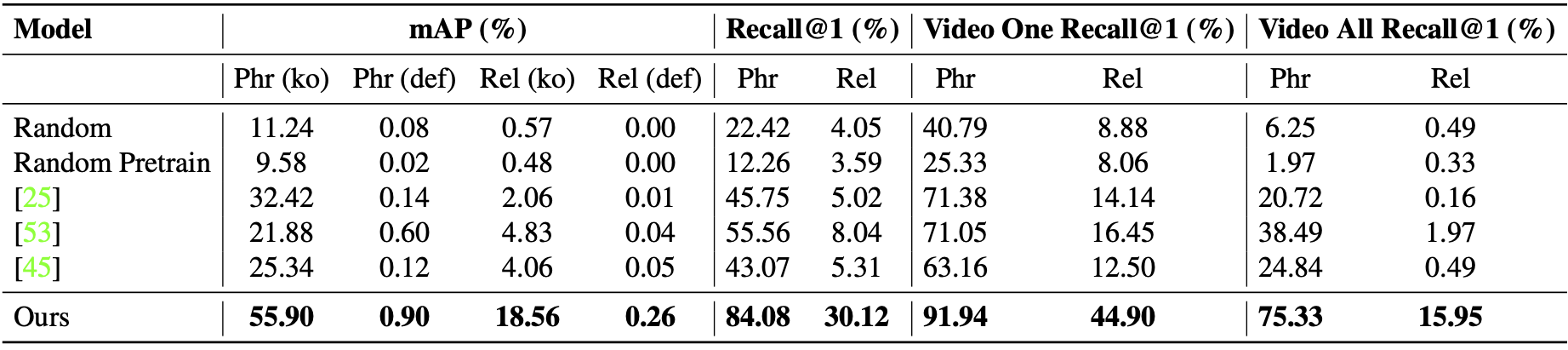
Comparison with baselines
Evaluation of performance on the V-HICO dataset. Phrase (Phr) detection refers to correct localization (0.3 IoU) of the union of human and object bounding boxes while relation (Rel) refers to correct localization (0.3 IoU) of both human and object bounding boxes. (ko) and (def) are the known object setting and default setting.
Comparison with baselines on unseen classes
Evaluation of our proposed approach and baselines on the unseen test set on V-HICO. The unseen test set consists of 51 classes of objects unseen during training. Evaluation at IoU threshold 0.3.

Paper
